Your Private, Offline AI Assistant.
Take notes and chat with a smart AI agent directly on your Android device. No cloud, completely private, and 100% free.
download
AI Privacy Explained: How AI Uses Your Personal Data
In 2024, AI privacy and security incidents jumped 56.4% in a single year — 233 reported cases. LinkedIn was fined €310 million for tracking user behavior without informed consent. Clearview AI was fined €30.5 million for scraping 30 billion social media images. These are not edge cases. They are the cost of AI's appetite for personal data — and they show why understanding AI privacy is no longer optional.
TL;DR: AI systems process your personal data across four stages — training, testing, operation, and improvement. The main risks are non-consensual data collection, memorized personal information that can leak, and biased automated decisions. GDPR gives you legal rights to control how AI uses your data; this guide explains how it all works and what you can do.
AI privacy is the practice of protecting personal or sensitive information collected, used, shared, or stored by AI systems. It is built on the principle that individuals should have meaningful control over their personal data.
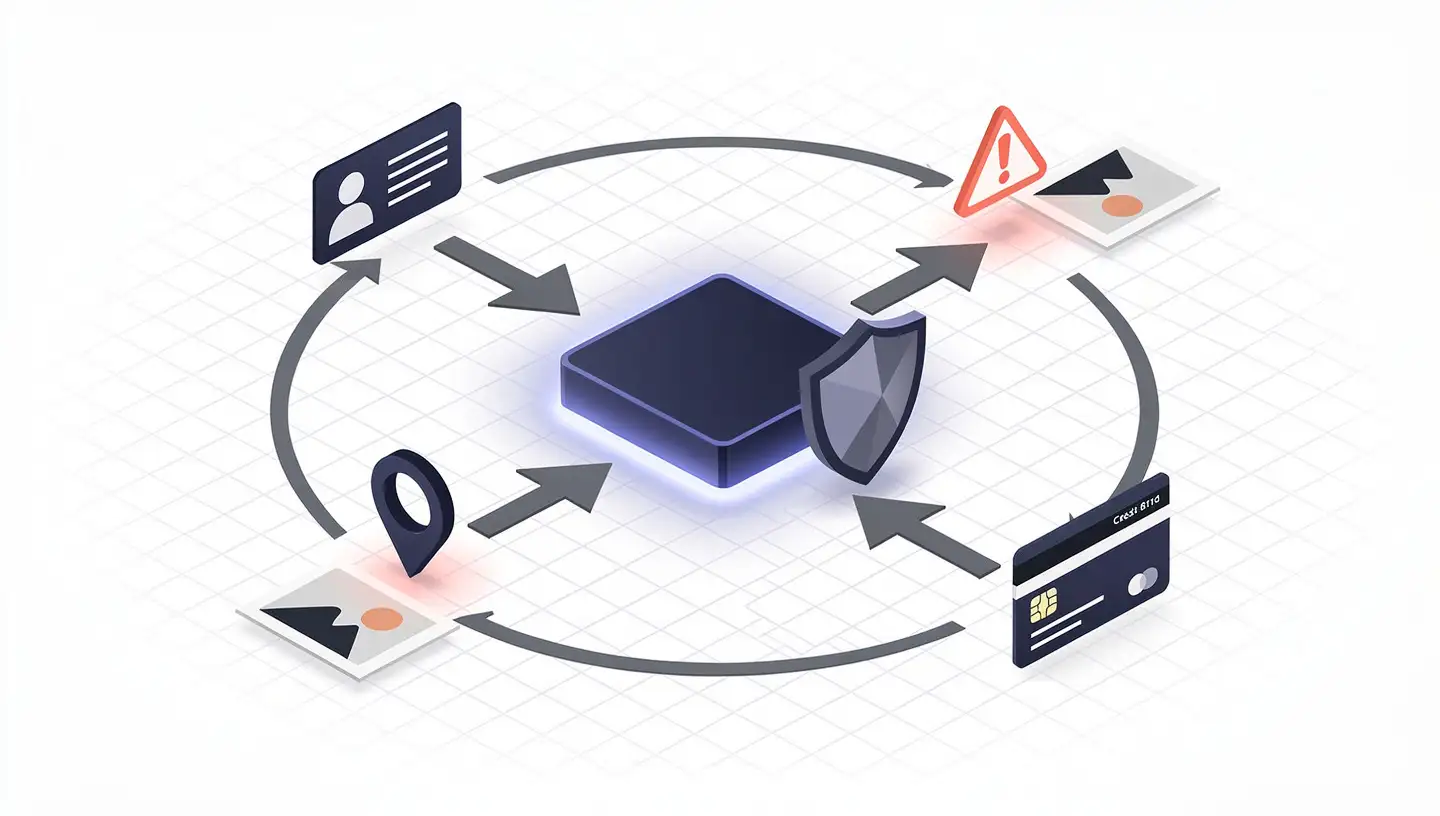
What Counts as "Personal Data" in the AI Era
Under the GDPR, personal data is any information that relates to an individual who can be directly or indirectly identified — names, email addresses, location, biometric data, even web cookies. AI systems treat all of that as fuel.
The scale matters. Where traditional software processes one record at a time, AI training datasets routinely contain terabytes or petabytes of text, images, and video — some of which is sensitive personal data like healthcare information. This volume makes it difficult for individuals to know what information has been collected, how it is being used, and how to remove it.
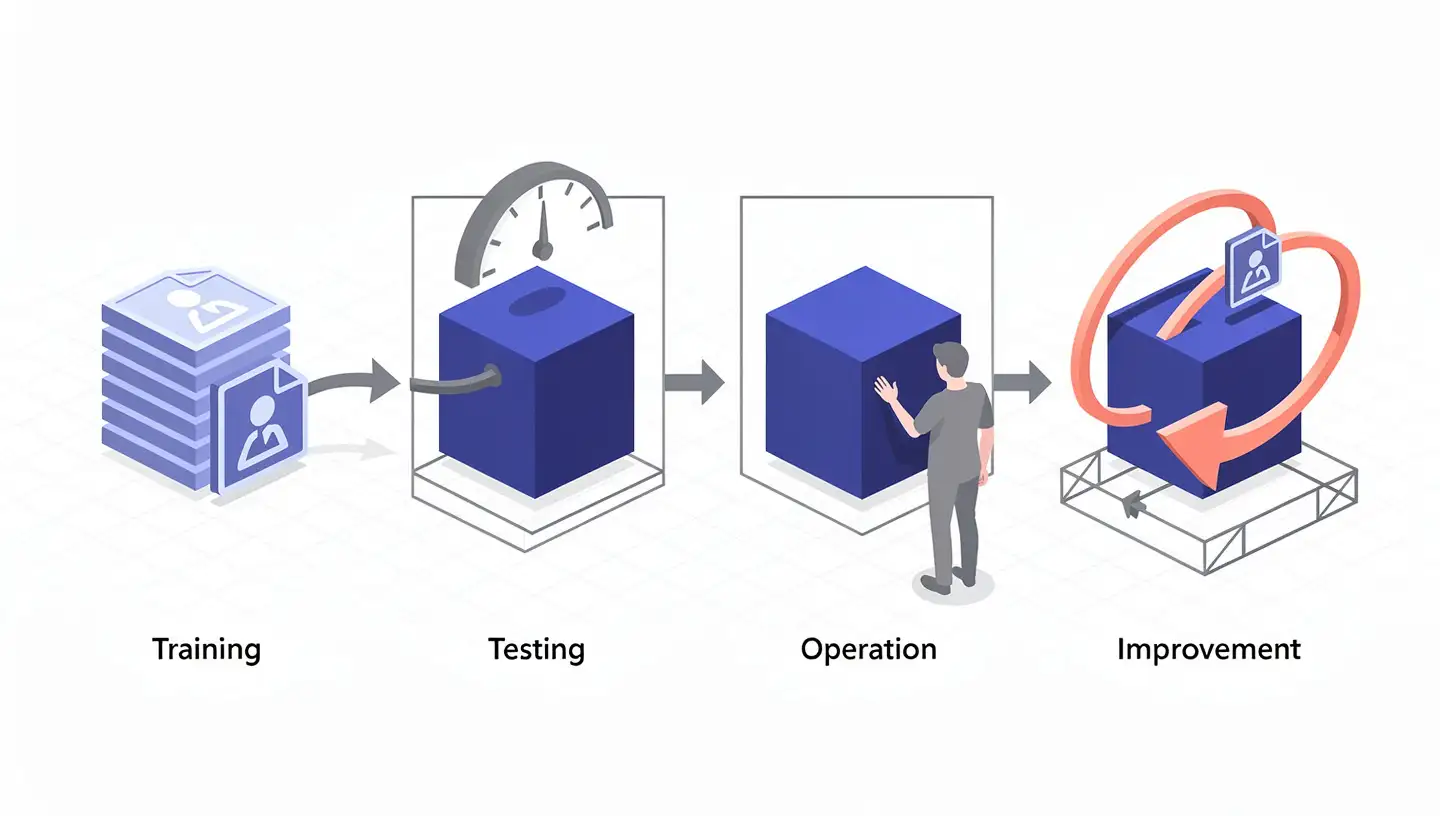
How AI Processes Your Personal Data: Four Stages
AI systems handle personal data across four distinct stages.
Training — The model learns from large datasets. Machine learning creates models that make predictions from data; deep learning automates feature extraction from unstructured datasets, allowing AI to draw inferences without explicit programming.
Testing — Engineers evaluate the model against held-out data to check accuracy and fairness before deployment.
Operation — When you interact with the AI (a chatbot, voice assistant, recommendation engine), your inputs are processed in real time and matched against patterns learned during training.
Improvement — Your interactions feed back into the model. Conversations, clicks, and corrections become new training data.
The implication is that your data does not stop influencing AI once you finish using the tool. It continues to shape the model — sometimes for users you will never meet.
Real-World Examples of AI Using Your Data
You encounter AI processing your personal data throughout the day, often without realizing it.
Smart assistants like Siri, Alexa, and Google Assistant process voice recordings, location data, and search histories to respond to your queries.
Recommendation systems on streaming and shopping platforms analyze viewing, listening, and purchase history to predict what you might want next.
Facial recognition identifies individuals from biometric data in images and video. The technology has shown significant bias and produced wrongful arrests — particularly of Black men — due to flawed training data.
Mobile apps with GPS enabled continuously collect location data, and in-app browsers can track every screen tap and key press inside them.
Dynamic pricing systems may quietly adjust prices based on your IP address or detected device. Travel packages, for instance, have been priced higher for users identified as MacBook owners.
The Privacy Risks: What Actually Goes Wrong
The data is growing faster than the safeguards
The average cost of a data breach reached USD 4.4 million as of December 2025. The number of AI-related privacy and security incidents climbed 56.4% in 2024 alone, reaching 233 reported cases.
Generative AI tools can memorize and leak personal data
Generative AI tools trained on web-scraped data can memorize personal information about real people and their relationships — which is exactly what enables targeted spear-phishing and identity theft. Controversy follows when data is used without express consent: LinkedIn faced backlash after some users were automatically opted into having their data train generative AI models, and photos shared by a surgical patient were repurposed for AI training without their knowledge.
Bias becomes discrimination at scale
AI models inherit the biases of the data they learn from. Facial recognition has produced documented wrongful arrests of Black men due to flawed training data. AI hiring tools trained on historical employee data can perpetuate or amplify existing biases, creating real exposure under employment laws like Title VII and the Americans with Disabilities Act.
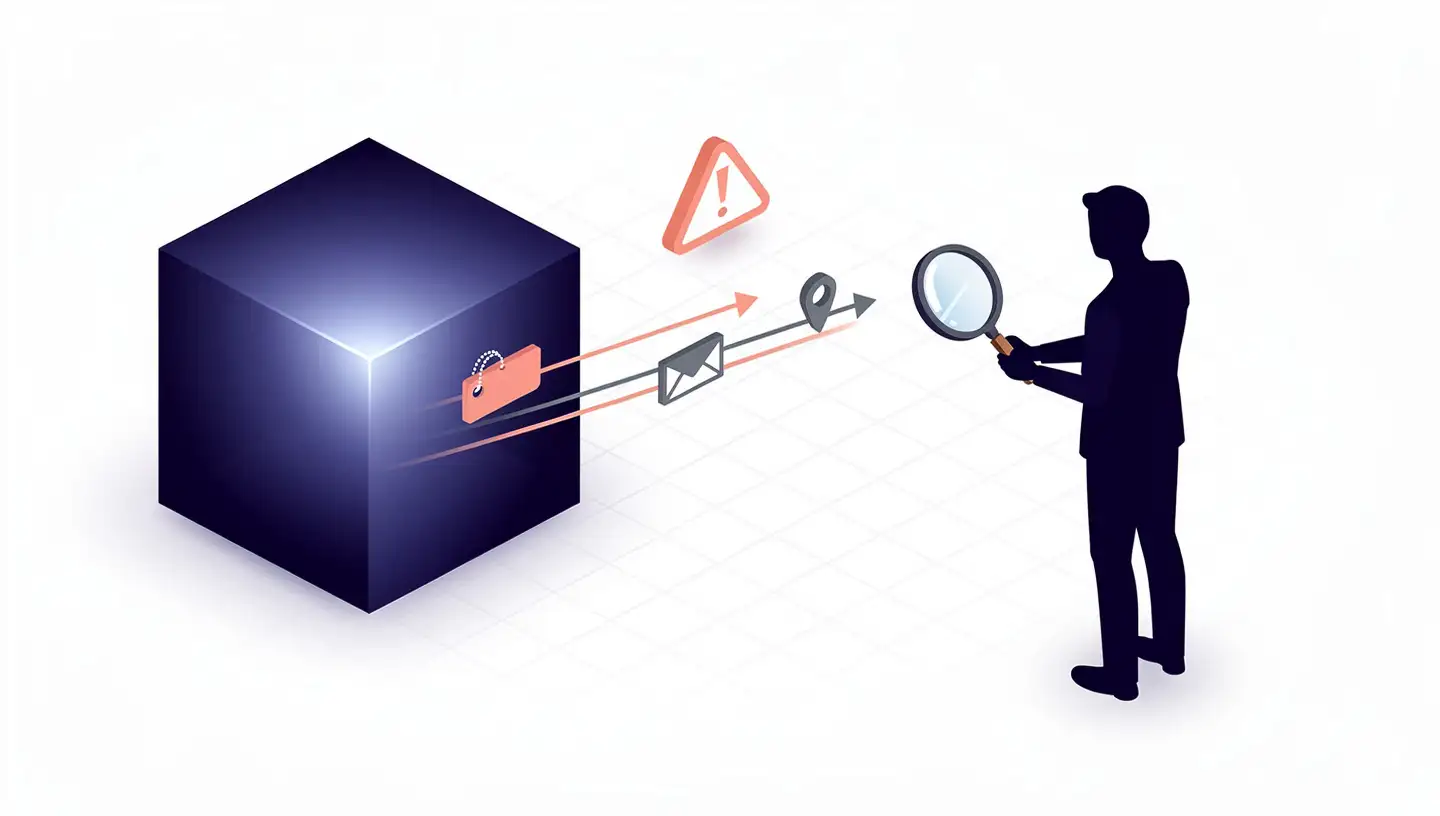
How Training Data Exposes Personal Information
Training data is the most overlooked privacy risk in AI. Three patterns matter.
Memorization and extraction. When models train on massive web-scraped datasets, they can memorize personal information embedded inside. Sensitive details — medical records, private communications, financial data — can sometimes be extracted through carefully crafted queries. For the EDPB, an AI model can only be considered truly anonymous if it is unlikely to either identify individuals or leak personal data through queries.
Model inversion attacks. These attacks reverse-engineer an AI model to retrieve sensitive information about its training data, letting attackers uncover private details without direct database access. Data poisoning is the inverse problem: attackers manipulate the training data itself to introduce biases or disrupt accuracy.
Consent and repurposing. Even data collected with consent is a risk if it is then used for purposes beyond what was disclosed. The legal standard is purpose limitation — and AI's hunger for training material constantly tests it.
Employee Privacy and AI at Work
Businesses deploying AI often need access to employee data — which raises its own legal questions about what data can be used, how it must be protected, and when consent is required. Several jurisdictions require explicit employee consent before personal data is collected or processed for AI training; an updated employee handbook is rarely sufficient.
Illinois's Biometric Information Privacy Act (BIPA) has produced million-dollar settlements for employers whose AI systems processed biometric data — facial recognition, voice patterns — without compliance. And employers remain responsible for how employee data is collected and used even when the AI vendor claims compliance.
The Legal Framework: GDPR and AI
The GDPR is the foundational regulation for AI processing of personal data in the EU — and in practice, well beyond it.
What GDPR requires
Data processing covers any action on personal data: collecting, recording, storing, using, or erasing.
AI developers must have a valid legal basis for processing personal data, such as explicit consent that is willingly given, specific, informed, and unequivocal.
Data minimization requires that only the data needed for a specific purpose be collected — and repurposing data requires fresh consent.
Individuals have the right to access, port, correct, and delete their personal data, and the right to an explanation of decisions made by automated processing.
How regulators are interpreting it for AI
The European Data Protection Board (EDPB) has issued opinions on the use of personal data for AI model development, focusing on when AI models can be considered anonymous and when legitimate interest can serve as a legal basis. The EDPB's three-step test for legitimate interest requires that processing be strictly necessary and balance individual rights against organizational needs.
Penalties
GDPR fines can reach €20 million or 4% of global annual revenue, whichever is higher. Recent enforcement makes the cost concrete: LinkedIn (€310 million, 2024) and Clearview AI (€30.5 million, 2024) for AI-related privacy violations.
The UK's Information Commissioner's Office offers parallel guidance for UK GDPR, including an AI and data protection risk toolkit that helps organizations assess the risks their AI systems pose to individual rights.
How to Protect Your Privacy When Using AI
A short, practical checklist:
Review privacy settings on every AI tool you use. Defaults are usually broad. Limit what you share; opt out of unnecessary tracking.
Be careful with generative AI inputs. Do not paste sensitive personal information, financial data, confidential work documents, or private communications into AI chatbots. Inputs can become training data or be retained indefinitely.
Understand opt-out vs. opt-in. Most online tracking is opt-out by default. Experts are pushing for an opt-in model that requires explicit consent before collection.
Limit location sharing. Disable GPS for apps that do not genuinely need it.
Use your legal rights. Under GDPR (and similar laws), you can access, correct, port, and delete your personal data — and demand an explanation of automated decisions that affect you.

On-Device AI and GDPR: Achieving Data Minimization
On-device AI satisfies GDPR data minimization by keeping personal data on the device. Real examples from healthcare, financial services, and enterprise software.
AI Privacy Explained: How AI Uses Your Personal Data
Learn how AI systems collect, process, and use your personal data — the privacy risks, real-world examples, GDPR protections, and how to protect yourself.
Frequently Asked Questions
What is AI privacy?
AI privacy is the practice of protecting personal or sensitive information that AI systems collect, use, share, or store. It is built on the principle that individuals should have meaningful control over their personal data, including the right to know what is collected and how it is used.
How does AI collect personal data?
AI handles personal data across four stages: training, testing, operation, and improvement. Training data is often scraped from the public internet, operation data comes from your real-time inputs and behaviors, and improvement data comes from your interactions feeding back into the model.
Is my data used to train AI?
Often, yes. Large language models and many generative AI tools are trained on datasets scraped from the web that may include personally identifiable information. LinkedIn was fined €310 million in 2024 for using AI to track behavior without informed consent, and Clearview AI was fined €30.5 million for scraping 30 billion images from social media.
Can AI remember and leak my personal information?
Yes. Generative AI tools can memorize personal information from their training data, and attackers can use techniques like model inversion to extract sensitive details from a trained model. The EDPB requires that anonymous AI models be unlikely to identify individuals or leak personal data through queries.
How can I protect my privacy when using AI?
Review the privacy settings of every AI tool you use, avoid pasting sensitive personal or financial information into AI chatbots, limit unnecessary location sharing, and exercise your legal rights under GDPR — including the rights to access, correct, and delete your personal data.
Conclusion
AI privacy now touches every person who uses digital technology. Your personal data flows through systems that can analyze, predict, and sometimes expose it — at a scale earlier privacy regimes were never designed for.
The picture isn't entirely grim. Regulators are catching up: GDPR enforcement is real, the EDPB is issuing concrete guidance on AI models, and the UK ICO is publishing practical toolkits. Individual rights — to access, correct, port, and delete your personal data, and to demand an explanation of automated decisions — exist on paper and are increasingly enforceable in practice.
The question is whether you exercise them. Review the privacy settings on your AI tools today. Treat anything you paste into a chatbot as potentially permanent. And remember that under GDPR, you have the right to ask any organization what data it holds about you — and to demand its deletion.