Your Private, Offline AI Assistant.
Take notes and chat with a smart AI agent directly on your Android device. No cloud, completely private, and 100% free.
download
NPU Explained: How Neural Processing Units Power AI
In 2026, generative AI chips are projected to generate roughly $500 billion in revenue — about half of the entire global chip market — despite making up just 0.2% of chips sold by unit volume. The Neural Processing Unit (NPU) sits at the center of that shift: a specialized chip purpose-built for the math behind modern AI.
TL;DR: An NPU is a microprocessor designed specifically for AI workloads — neural network inference, computer vision, speech recognition, on-device generative AI. It uses dedicated multiply-accumulate units, on-chip memory, and lower-precision arithmetic to run AI tasks dramatically faster and more efficiently than CPUs or GPUs. NPUs are now standard in flagship smartphones and AI PCs.
An NPU (Neural Processing Unit) is a specialized hardware accelerator built to speed up AI neural networks, deep learning, and machine learning applications. It mimics the parallel structure of the human brain to perform trillions of operations per second on AI workloads.

What an NPU Actually Is
A Neural Processing Unit (NPU) is a specialized computer microprocessor designed to mimic the processing function of the human brain, optimized for artificial intelligence neural networks, deep learning, and machine learning tasks. The architecture simulates a brain's neural network so it can process large amounts of data in parallel and perform trillions of operations per second.
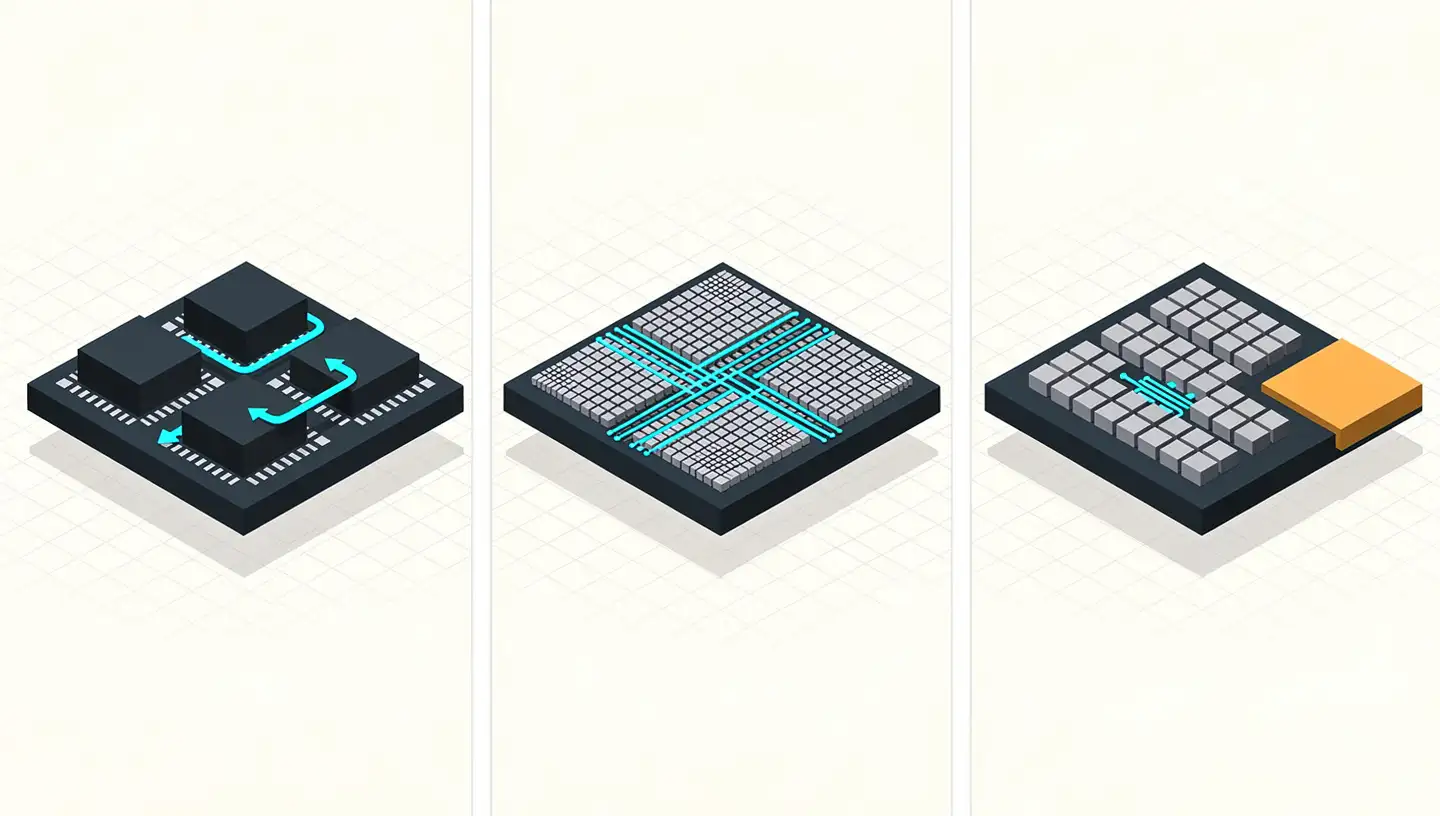
Where a CPU is built to execute one or two instructions at a time across a small number of powerful cores, and a GPU is built to throw thousands of smaller cores at parallel problems, an NPU is built around the specific math that neural networks perform: enormous numbers of multiply-and-accumulate (MAC) operations on weight matrices. That single-purpose focus is where the efficiency comes from.
NPUs are sometimes labeled "AI accelerators" or "deep learning processors". They share a family with Google's TPUs and other custom ASICs (application-specific integrated circuits) being designed by Google, Amazon, OpenAI, and others — all variations on the theme of "abandon general-purpose flexibility, gain dramatic AI efficiency".
How NPUs Work: Three Architectural Choices
NPUs gain their advantage from three specific design decisions.
1. Specialized compute units
NPUs integrate dedicated hardware for multiply-and-accumulate operations — the operation at the heart of every neural network layer. Multiply two numbers, add the result to an accumulator, repeat billions of times. Dedicating silicon to this exact pattern is what lets NPUs achieve high parallelism with less energy than general-purpose alternatives.
2. High-speed on-chip memory
NPUs use high-speed on-chip memory so model weights and activations stay physically close to the compute units. AI workloads constantly load large parameter matrices, so memory bandwidth — not raw arithmetic — is often the bottleneck. Keeping data on-chip removes the round trip to main memory that slows down CPUs and GPUs on these workloads.
3. Lower-precision arithmetic
NPUs work in 4-bit or 8-bit precision rather than the 32-bit or 64-bit precision used by general-purpose processors. Neural networks tolerate this precision drop with minimal accuracy loss — but the energy savings are substantial. Lower precision means smaller transistor counts per operation, less memory bandwidth used, and lower power per inference.
The combined result is lightning-fast, high-bandwidth AI in real time, enabling applications such as voice command recognition, computational photography, and rapid on-device image generation.
NPU vs CPU vs GPU: How They Compare
Processor | Architecture | Best for | Energy use (AI workload) | Role in AI |
|---|---|---|---|---|
CPU | Few powerful cores, sequential | General-purpose computing, OS, control flow | Highest | Coordination, light AI |
GPU | Thousands of smaller cores, massively parallel | Graphics, large-scale AI training | High | Training large models, heavy inference |
NPU | Specialized MAC units + on-chip memory | AI inference at low latency | Lowest (often <50% of CPU) | On-device AI in phones, laptops, IoT |
CPUs have a small number of powerful cores designed for sequential general-purpose tasks, while GPUs have thousands of smaller cores that excel at parallel processing. GPUs handle AI well, but they remain general-purpose parallel processors originally built for graphics — they get the job done at a cost in power and silicon area.
NPUs take specialization further by mimicking the human brain's parallel structure, enabling high parallelism with less energy consumption than GPUs. The performance gap can be dramatic: testing has shown some NPUs perform over 100 times better than a comparable GPU at the same power consumption. Against CPUs, an Intel NPU demonstrated three times lower power consumption and 46% faster processing in lab benchmarks.
One important caveat: NPUs currently occupy only about 5–10% of a System on Chip (SoC), compared to GPUs that can take up around 50% of the SoC. This means NPUs are optimized for specific AI inference tasks, not general AI processing — they are not poised to replace GPUs for large-model training.
Major Players Making NPUs
The NPU market has attracted nearly every major chip company.
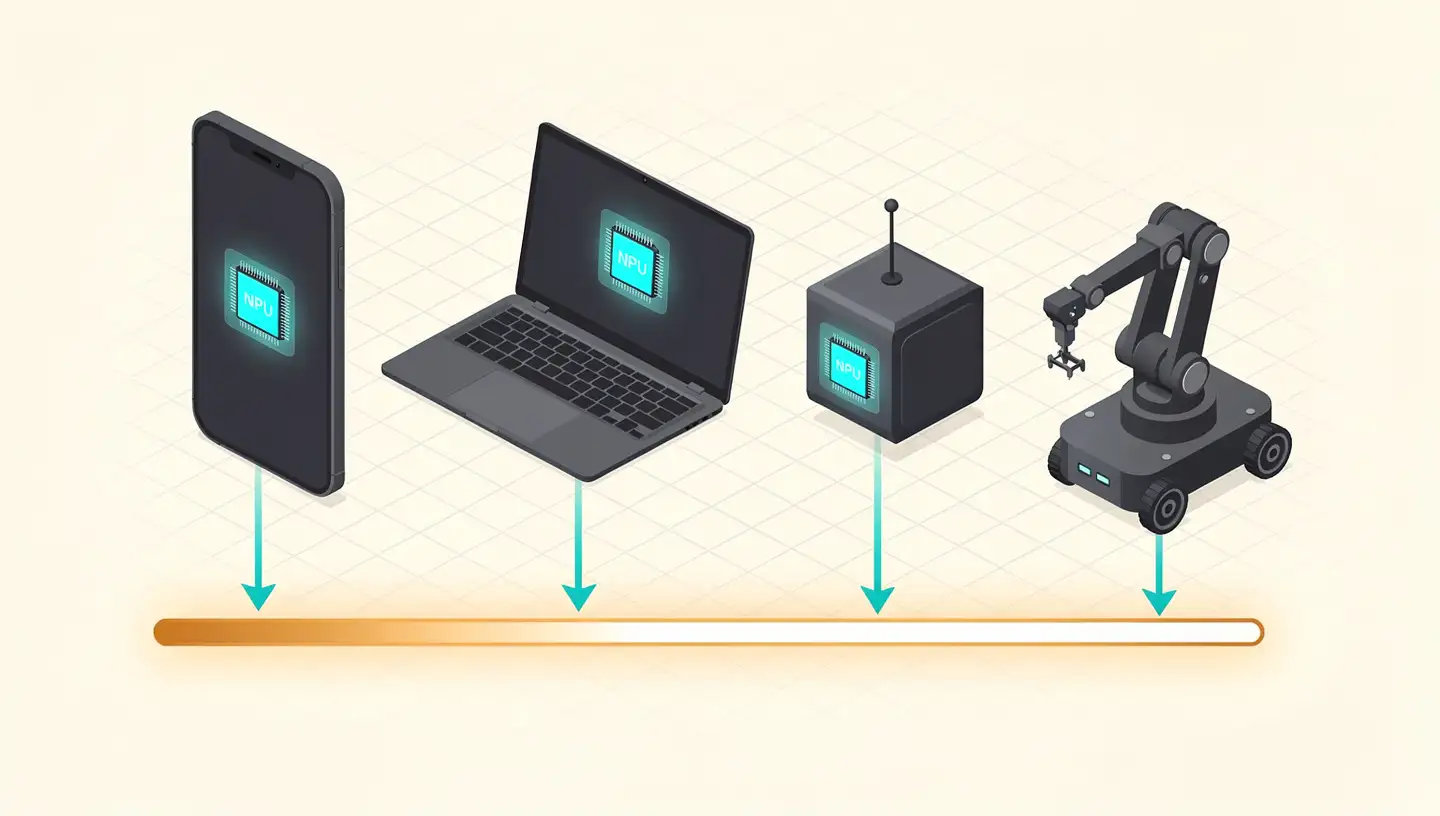
Apple, Qualcomm, Samsung, Huawei, and Google Tensor all ship smartphone chips with AI accelerators that enhance on-device machine learning.
Qualcomm's Hexagon NPU powers Snapdragon platforms across smartphones, Windows laptops, automotive, and robotics. It's custom-designed for fast on-device generative AI with class-leading inference power efficiency. Qualcomm's Sensing Hub uses dedicated micro NPUs for always-on AI such as contextual awareness and sensor processing.
Intel and AMD are integrating NPUs into their PC chips, kicking off the "AI PC" category. Intel's Gaudi 3 is an ASIC designed for both training and inference.
Google's TPUs take a different path — application-specific integrated circuits built for large-scale AI in data centers. Google released its seventh-generation TPU, Ironwood, in November 2025.
Custom ASICs from Google, Amazon, and OpenAI signal a broader shift: hyperscalers are increasingly investing in their own AI silicon rather than relying on general-purpose chips.
Where NPUs Show Up: Real Use Cases
NPUs handle workloads such as image recognition, voice processing, and natural language tasks efficiently, making them essential for AI capabilities in mobile devices.
In smartphones, NPUs power real-time language translation, computational photography, and always-on voice assistants that respond to wake words without draining the battery. Because the AI runs locally, there's no need to send data to cloud servers — which improves both latency and privacy.
In AI PCs, NPUs run features like Microsoft's Windows Studio Effects (background blur during video calls, automatic eye-contact correction) without taxing the CPU or GPU. The CPU and GPU stay free for other work, which improves overall system responsiveness.
At the edge, NPUs are designed for ultra-efficient processing on laptops, monitors, IoT devices, and mobile applications. They let OEMs deliver AI-driven features without over-speccing the CPU — keeping cost, heat, and power consumption in check.
Broader use cases span robotics, autonomous vehicles, Internet of Things sensors, and edge computing — anywhere real-time AI inference needs to run with strict power and latency budgets.
The Market: Why This Matters Now
The economic trajectory of the NPU market reflects the broader AI infrastructure boom.
The semiconductor industry expects 22% revenue growth in 2025, accelerating to 26% in 2026, primarily driven by AI.
The global semiconductor industry is projected to reach US$975 billion in annual sales in 2026.
Generative AI chips alone are projected to generate roughly $500 billion in 2026 — about half of global chip sales.
AMD CEO Lisa Su has estimated the total addressable market for AI accelerator chips for data centers could reach $1 trillion by 2030.
Custom ASIC shipments from cloud providers are projected to grow 44.6% in 2026, vs. 16.1% for GPUs — a clear signal that hyperscalers are moving toward purpose-built AI silicon.
The volume-to-revenue ratio tells the rest of the story. Of the 1.05 trillion chips sold in 2025 at an average price of $0.74 per chip, generative AI chips were only 0.2% by unit volume — but commanded a disproportionate share of revenue. Specialization, in this market, means premium pricing.
Limitations and Trade-offs
NPUs are not a universal answer. Four limitations matter for anyone making hardware or deployment decisions.
Small SoC footprint. NPUs occupy roughly 5–10% of a System on Chip vs. GPUs at ~50%, so they're sized for specific inference tasks, not general AI processing.
Built for inference, not training. Large-model training still needs the parallel raw power and memory bandwidth that only GPUs provide. Some ASICs like Intel's Gaudi 3 are designed for both, but most NPUs are inference-only.
Task-specific optimization. NPUs are optimized for neural network operations. They are excellent at robotics, IoT, and data-intensive sensor-driven tasks, but they can't match a GPU's flexibility on non-AI parallel workloads.
Evolving software ecosystem. Developer tooling for NPUs is still maturing. The Khronos Group is pursuing standardization of AI-related interfaces to reduce the development effort needed across NPU architectures, and Qualcomm's Neural Processing SDK offers debugging and optimization tools for Hexagon NPUs — but the ecosystem is less mature than what exists for CPUs and GPUs.
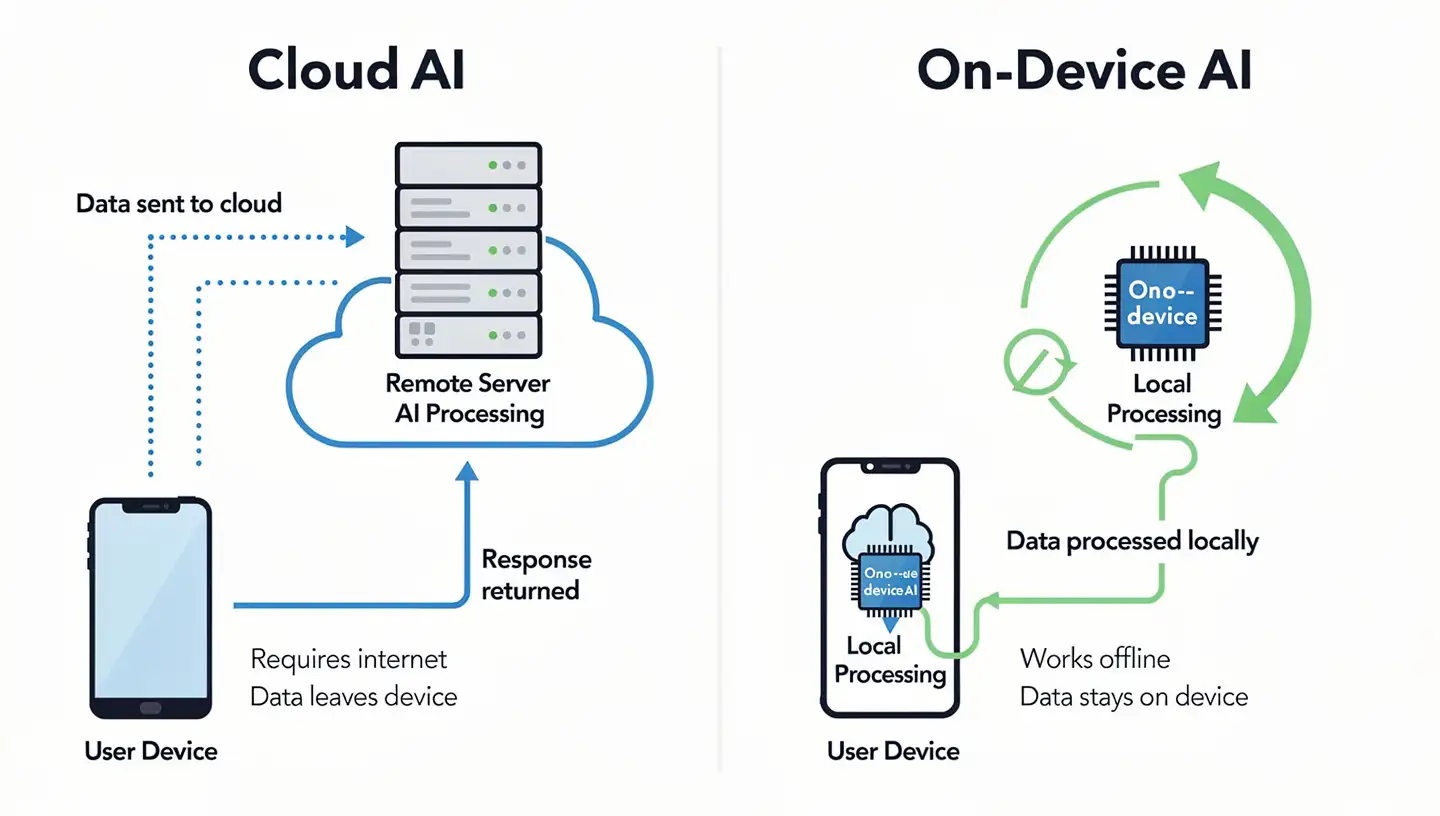
What Is On-Device AI? Privacy, Speed, and Real Examples
On-device AI runs models locally on your phone, laptop, or wearable — delivering privacy, low latency, and offline access. Learn how it works in 2026.

On-Device AI and GDPR: Achieving Data Minimization
On-device AI satisfies GDPR data minimization by keeping personal data on the device. Real examples from healthcare, financial services, and enterprise software.
Frequently Asked Questions
What is a Neural Processing Unit (NPU)?
A Neural Processing Unit (NPU) is a specialized microprocessor designed to mimic the processing function of the human brain, optimized for AI neural networks, deep learning, and machine learning workloads. Unlike general-purpose CPUs or GPUs, NPUs are purpose-built for AI inference at high speed and low power.
How does an NPU differ from a CPU or GPU?
CPUs use a small number of powerful cores for sequential general-purpose tasks; GPUs use thousands of smaller cores optimized for parallel processing. NPUs go further — they integrate specialized compute units for the multiply-and-accumulate operations that underlie neural networks, with on-chip memory and lower-precision arithmetic that make them dramatically more efficient for AI workloads.
Which devices have NPUs?
Most flagship smartphones (Apple, Qualcomm Snapdragon, Samsung, Google Tensor, Huawei), AI PCs from Intel and AMD, and an expanding range of edge devices, laptops, monitors, IoT sensors, and robotics platforms.
Can NPUs replace GPUs for AI training?
Not yet. NPUs currently occupy roughly 5–10% of a System on Chip versus GPUs' ~50% and are optimized primarily for inference. Large-model training still requires GPUs' massive parallel processing power and memory bandwidth, though some ASICs like Intel's Gaudi 3 are designed for both training and inference.
How energy-efficient are NPUs?
Very. AI PCs equipped with NPUs can run many AI workloads using less than half the power required by an equivalent CPU. In benchmarks, an Intel NPU showed three times lower power consumption and 46% faster processing than the CPU, and some NPUs perform over 100 times better than a comparable GPU at the same power level.
Conclusion
NPUs are not replacing CPUs or GPUs. They are joining them — and the future of computing is heterogeneous: each processor type doing what it's best at, with workloads routed accordingly.
The market trajectory makes this clear. Generative AI chips on track for $500 billion in 2026 revenue. Custom ASIC shipments outgrowing GPU shipments. AI PCs becoming a category. Smartphones shipping with dedicated AI silicon as standard, not a premium feature.
For anyone building AI-powered products — or anyone trying to understand what makes modern devices feel "smart" — the NPU is the part of the chip that most often matters. If you're evaluating new hardware, looking at the NPU's TOPS rating (trillions of operations per second) tells you more about AI capability than the CPU clock speed ever did. And if you're choosing where to run an AI workload, the question is no longer just "cloud or local?" — it's also "which processor on the local device?"